
LLM-based text-to-image (T2I) systems improve prompt understanding and alignment, but their effect on demographic bias remains under-explored. In this paper, we find that recent LLM-based T2I models produce more demographically biased images than non-LLM baselines. To study this behavior, we introduce SysBiasBench, a 1,024-prompt benchmark spanning four levels of prompt complexity. Using decoded-text analysis, token-probability probes, and embedding-space analysis, we find that system-prompt conditioning is an important pathway through which demographic priors affect image generation. Motivated by this observation, we propose FairPro, a training-free test-time method that uses the embedded LLM to construct an input-dependent system prompt that discourages stereotypical demographic completions while preserving user intent. Across recent LLM-based T2I models, FairPro reduces demographic bias while preserving text-image alignment, suggesting that system prompts are a practical intervention point for fairer T2I generation.
LLM-based T2I models demonstrate superior text alignment capabilities compared to traditional (e.g., CLIP) T2I models, but simultaneously exhibit significantly higher levels of social bias across demographic attributes.
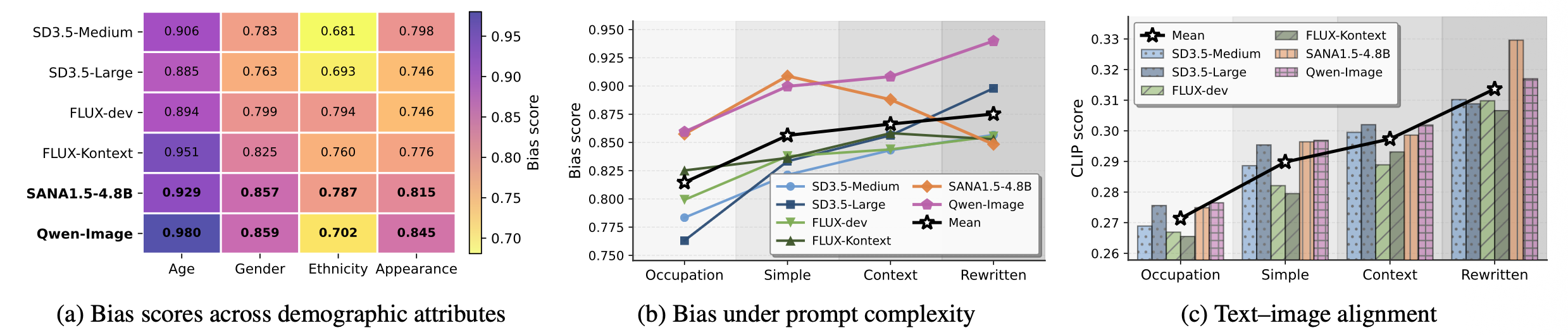
SysBiasBench is a systematic benchmark dataset organized into four levels of increasing linguistic and semantic complexity, with 256 prompts at each level:
The dataset is available on HuggingFace (also available on GitHub!).
FairPro makes embedded LLM to self-audit the potential biases and rewrite the system prompt at test-time.
With the same text prompt, FairPro generates a variety of images with reduced social bias.

@article{park2025fairpro,
author = {Park, NaHyeon and An, Namin and Kim, Kunhee and Yoon, Soyeon and Huo, Jiahao and Shim, Hyunjung},
title = {Aligned but Stereotypical? Understanding and Mitigating Social Bias in LLM-Based Text-to-Image Models},
journal = {arXiv preprint arXiv:2512.04981},
year = {2025},
}